Cybersecurity has become so bad that it now poses an extraordinarily grave threat to the U.S. economy and our national defense. No comprehensive solution to this threat has been found, much less implemented.
The existing architecture for computers was designed in 1945 and has no internal defense against Internet malware – except software, which inherently can be defeated by it.
Internet connection requires that computer external defenses be porous, thereby potentially allowing in malware, which can potentially go anywhere inside the computer and do anything.
A new architecture for computers has been invented to solve this problem. It can provide, for the first time ever, true security and privacy for computers when connected to the Internet.
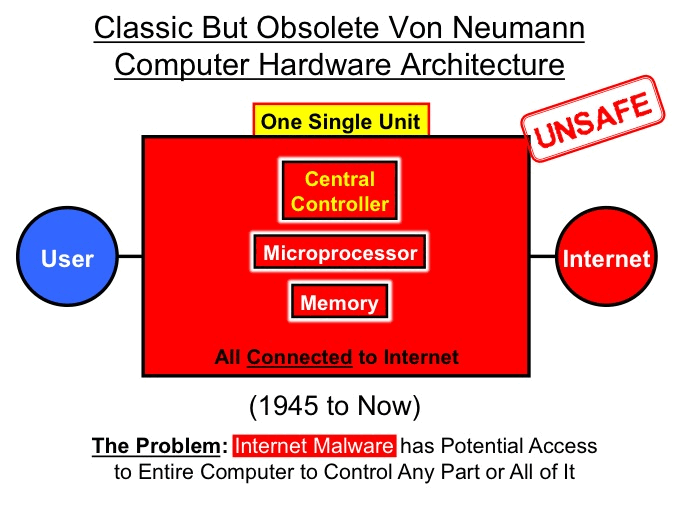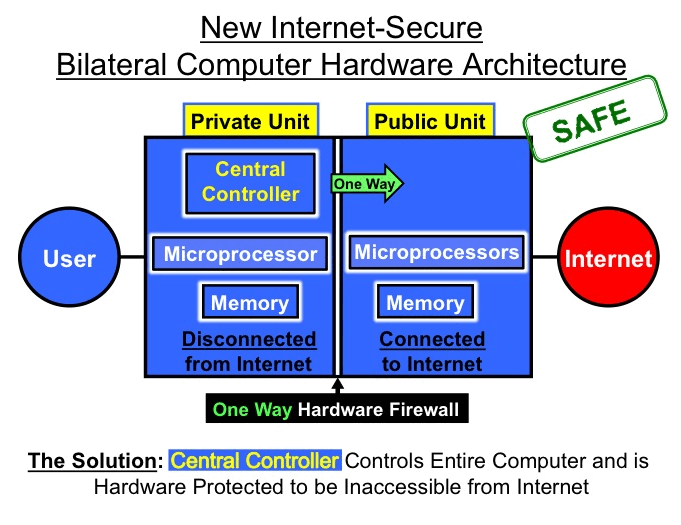
The new computer architecture has a bilateral structure that provides an internal hardware defense against Internet malware.
The new bilateral architecture provides an inner protected area that controls the entire computer, but is disconnected by an impermeable hardware barrier from access by the Internet and therefore is invulnerable to Internet malware.
The only known way to protect a computer or network now is to disconnect it from the Internet, but Internet connection is absolutely mandatory in today’s world.
The new bilateral computer architecture manages the seeming impossibility of simultaneously being Internet connected and Internet disconnected, thereby providing fail-safe security and privacy.
